引言
随着数字化技术的快速发展,古籍OCR(光学字符识别)技术成为文化遗产保护与传播的重要工具。然而,古籍的多样性不仅体现在中文古籍中,还涵盖了日文、韩文、越南文等多语言古籍。这些跨文化古籍的数字化面临独特的技术挑战,同时也为OCR技术的创新提供了广阔的空间。本文将探讨多语言古籍OCR的技术差异、挑战与解决方案,并结合金鸣识别在竖排文字识别方面的优势,分析其在日文古籍识别中的应用。

中文古籍与其他语言古籍OCR的技术差异
1. 文字体系的多样性
- 中文古籍:以汉字为主,字体多样(篆书、隶书、楷书等),且多为竖排文字。
- 日文古籍:包含汉字、平假名和片假名,文字组合复杂,竖排与横排并存。
- 韩文古籍:以韩文(谚文)为主,部分包含汉字,排版方式多样。
- 越南文古籍:历史上使用汉字(汉喃)和拉丁化文字,文字体系变化较大。
2. 版面布局的差异
- 中文古籍:竖排为主,无标点符号,注释以小字形式穿插于正文。
- 日文古籍:竖排与横排混合,假名与汉字交替出现,版面复杂。
- 韩文古籍:竖排与横排并存,文字与符号的组合方式独特。
- 越南文古籍:汉喃文字与拉丁化文字的混合使用,增加了识别难度。
3. 字体与书写风格的差异
- 不同语言的古籍在字体风格、笔画粗细、字形结构上存在显著差异,这对OCR模型的训练与优化提出了更高要求。
多语言古籍OCR的技术挑战与解决方案
1. 技术挑战
- 文字多样性:多语言古籍的文字体系复杂,OCR模型需要支持多种字符集。
- 版面复杂性:竖排、横排、混合排版等多种版面形式增加了识别的难度。
- 图像质量问题:古籍图像可能存在模糊、污渍、虫蛀等问题,影响识别效果。
- 语言模型的适配:不同语言的语法、语义差异需要针对性的语言模型支持。
2. 解决方案
- 多语言OCR模型:训练支持多语言的OCR模型,结合统一的字符集和语言模型。
- 版面分析技术:利用深度学习技术实现版面的自动分割与识别,支持竖排、横排等多种排版形式。
- 图像预处理:通过图像增强技术(如去噪、锐化、对比度调整)提升图像质量。
- 语言模型优化:针对不同语言的特点,优化语言模型以提高识别准确率。
跨文化古籍数字化的意义与案例
1. 文化传承与保护
- 古籍数字化有助于保存濒危文化遗产,避免因物理损坏导致的文化断层。
- 数字化古籍可以更方便地传播与研究,促进跨文化交流。
2. 学术研究与教育
- 数字化古籍为历史学、语言学、文献学等学科提供了丰富的研究素材。
- 教育领域可以利用数字化古籍开发教学资源,提升学生对传统文化的认知。
3. 实际案例
- 中国国家图书馆古籍数字化项目:通过OCR技术将大量中文古籍数字化,并提供在线检索服务。
- 日本国立国会图书馆:利用OCR技术对日文古籍进行数字化,支持竖排文字的识别。
- 韩国古典翻译院:将韩文古籍数字化,并结合OCR技术实现文本的自动翻译。
金鸣识别在多语言古籍识别中的优势
1. 竖排文字识别的技术优势
- 金鸣识别在竖排文字识别方面具有显著优势,能够准确识别多语言古籍中的竖排文本。
- 其OCR模型经过大量古籍数据的训练,能够适应多语言古籍中汉字与假名的混合排版。
2. 版面分析与预处理
- 金鸣识别采用先进的版面分析技术,能够自动分割多语言古籍中的文字区域、注释和插图。
- 通过图像预处理技术,有效解决古籍图像模糊、污渍等问题,提升识别准确率。
3. 多语言支持
- 金鸣识别支持多语言OCR,能够同时处理中文、日文、韩文等多种语言的古籍。
- 其语言模型针对不同语言的特点进行了优化,确保识别结果的准确性。
如何用金鸣识别的竖排文字识别模块将多语言古籍识别出来?
下面是以日文古籍为例的操作步骤:

1、在网页版或电脑客户端选择“通用文字”或“文字识别”,再选择“竖排文字”。
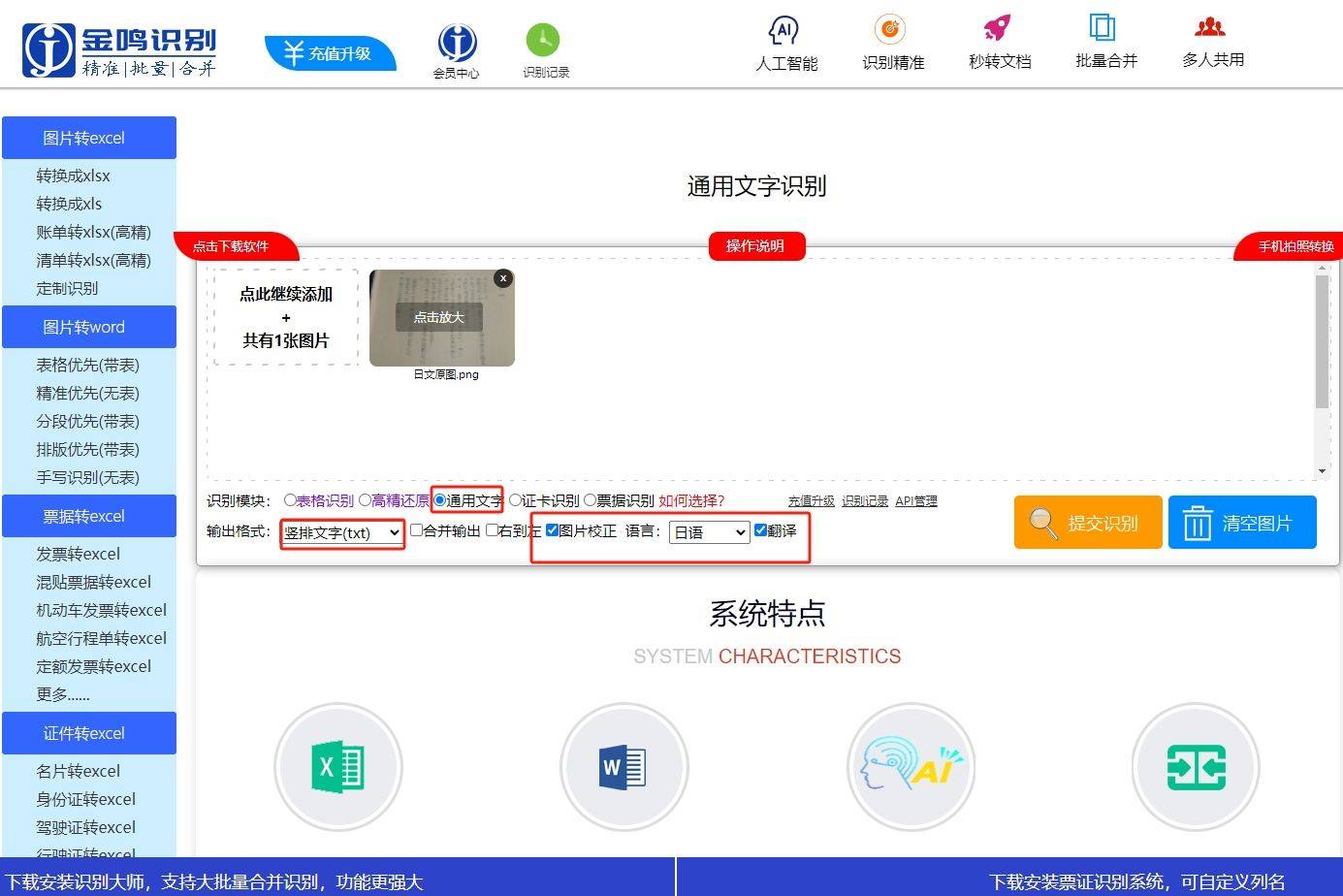
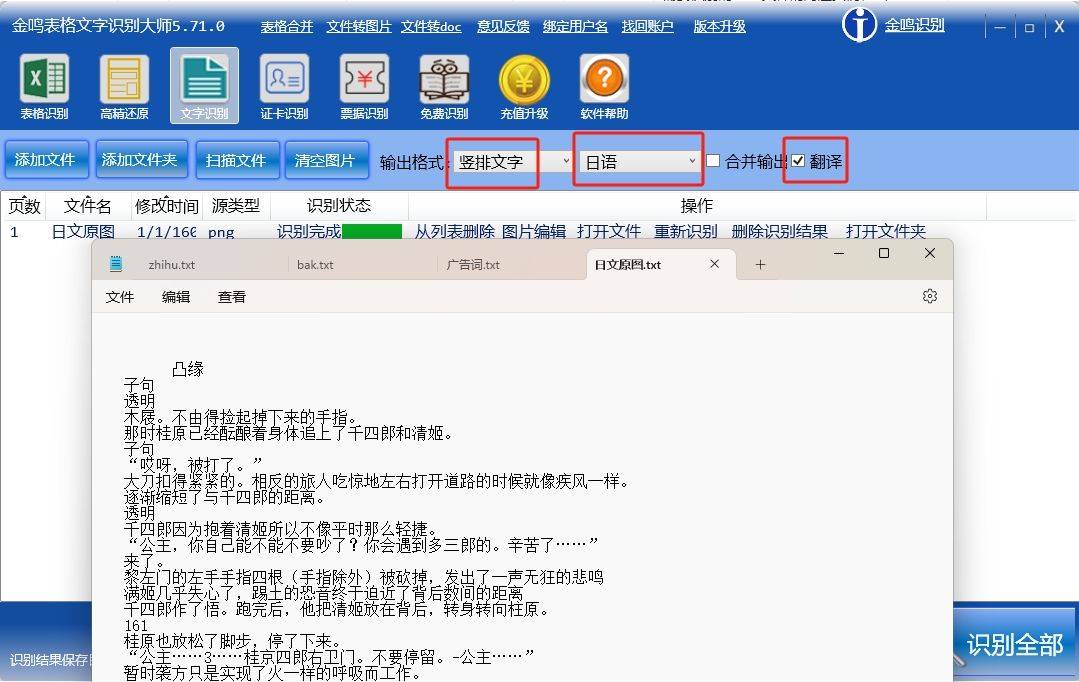
2、在语言下拉菜单中选择”日语“,如需将识别结果翻译成简体中文,请勾选”翻译“,如需批量识别并将识别结果合并成一个文件,请勾选”合并“。
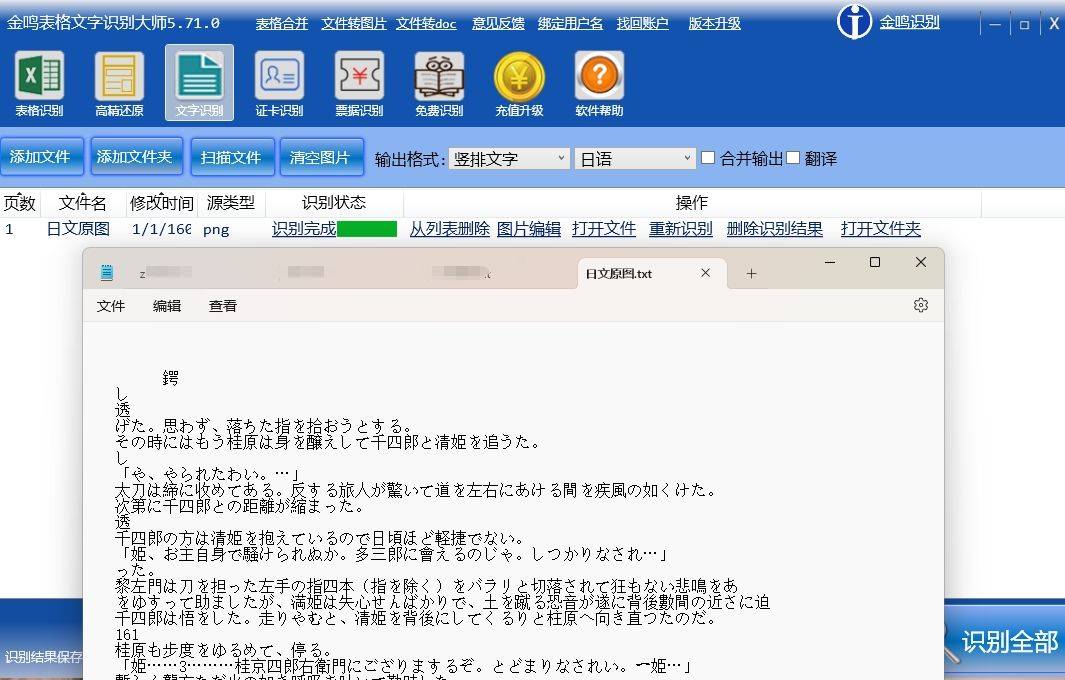
3、点击”提交识别“或”识别全部“即可完成识别。
结语
古籍OCR技术在跨文化古籍数字化中发挥着重要作用,同时也面临多语言、多版面的技术挑战。金鸣识别凭借其在竖排文字识别方面的优势,为日文古籍的数字化提供了高效解决方案。未来,随着OCR技术的不断进步,跨文化古籍的数字化将更加普及,为全球文化遗产的保护与传播贡献力量。


 在线客服咨询
在线客服咨询 Ctrl+D 收藏本站
Ctrl+D 收藏本站