1. 引言
手写表格的OCR(光学字符识别)转换是一项具有挑战性的任务,主要由于手写文本的多样性和不规则性。与印刷字体相比,手写文本的识别精度更难保证,尤其是在表格结构复杂的情况下。本文将探讨手写表格OCR转换的难点,分析常用OCR工具的优缺点,并介绍基于机器学习的改进算法和开源工具,以提升转换精度。

2. 手写表格OCR的难点
- 手写文本的多样性:不同人的书写风格、字体大小、倾斜度等差异较大。
- 表格结构的复杂性:表格中的线条、合并单元格、空白区域等增加了识别的难度。
- 噪声干扰:手写表格中可能存在涂抹、修正带等噪声,影响识别效果。
3. 常用OCR工具及其优缺点
- Tesseract: 优点:开源、支持多种语言、可自定义训练模型。 缺点:对手写文本的识别精度较低,尤其是复杂表格。
- Google Vision API: 优点:强大的云端处理能力,支持手写文本识别。 缺点:需要网络连接,成本较高,且对表格结构的识别有限。
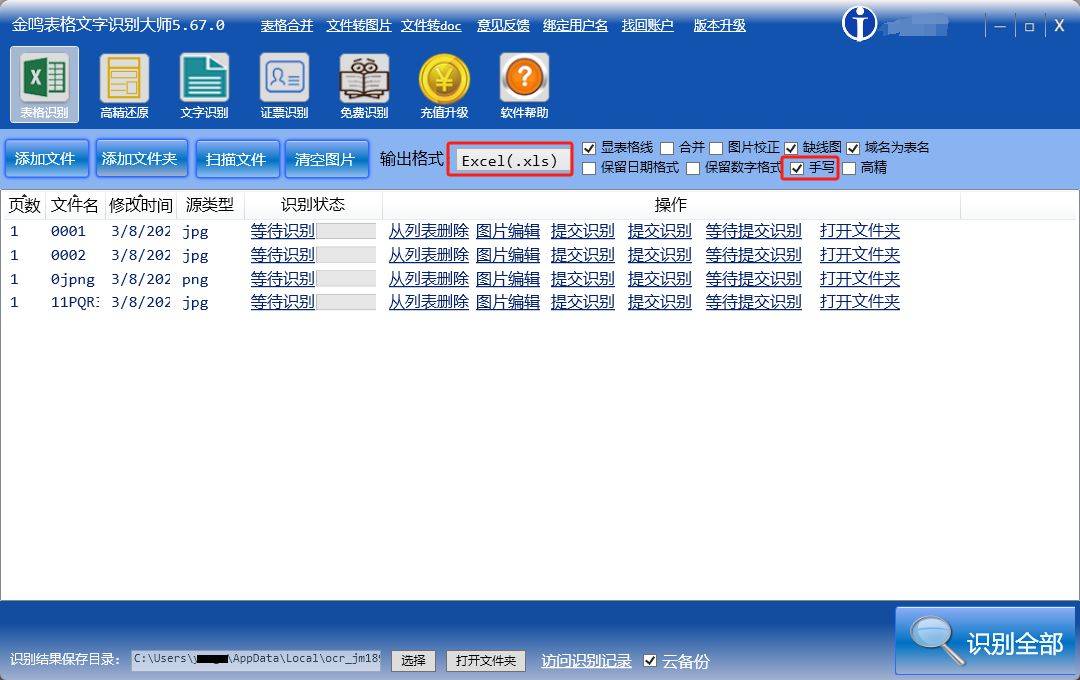
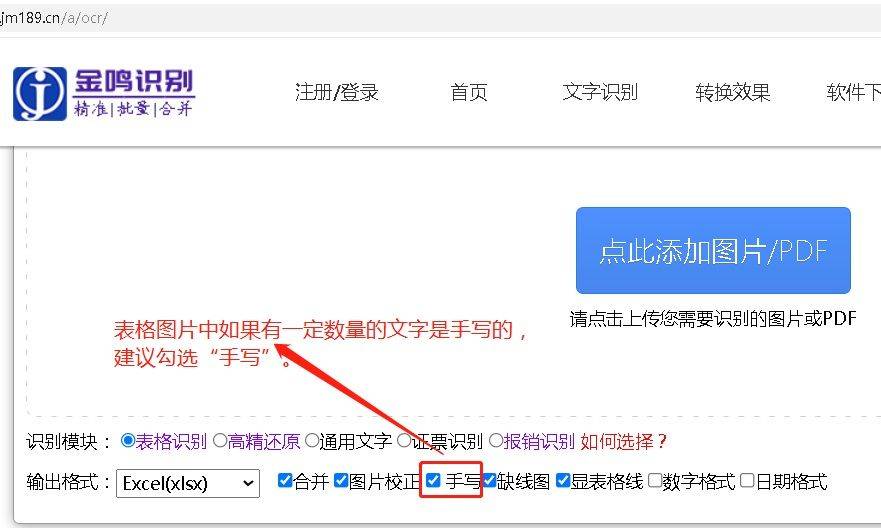
- 金鸣表格文字识别: 优点:专注于表格识别,支持手写文本和复杂表格结构,识别精度较高。 缺点:部分高级功能及大批量识别可能需要付费。
4. 基于机器学习的改进算法
- 卷积神经网络(CNN):用于图像特征提取,提高手写文本的识别精度。
- 循环神经网络(RNN):用于序列数据的处理,适合识别连续的手写文本。
- 注意力机制:增强模型对关键区域的关注,提升复杂表格的识别效果。
- 数据增强:通过旋转、缩放、添加噪声等方式增加训练数据的多样性,提高模型的泛化能力。
5. 开源工具与框架
- Keras/TensorFlow:用于构建和训练深度学习模型,支持自定义OCR模型。
- OpenCV:用于图像预处理,如二值化、去噪、边缘检测等。
- PaddleOCR:百度开源的OCR工具,支持手写文本识别和表格结构分析。
- EasyOCR:基于深度学习的OCR库,支持多种语言和手写文本识别。
6. 优化转换精度的策略
- 预处理:对图像进行去噪、二值化、倾斜校正等处理,提高识别效果。
- 后处理:利用语言模型和上下文信息对识别结果进行校正,减少错误。
- 多模型融合:结合多个OCR模型的输出,通过投票或加权平均提高精度。
- 用户反馈:允许用户对识别结果进行修正,并将修正数据反馈给模型进行再训练。
7. 结论
手写表格的OCR转换是一个复杂且具有挑战性的任务,但通过结合先进的机器学习算法和开源工具,可以显著提升转换精度。金鸣表格文字识别作为专注于表格识别的工具,在手写文本和复杂表格结构的识别上表现出色。未来,随着深度学习技术的不断发展,手写表格OCR的识别精度和效率将进一步提高,为实际应用提供更多可能性。
8. 参考文献
- Smith, R. (2007). An overview of the Tesseract OCR engine. International Conference on Document Analysis and Recognition.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
- PaddleOCR: https://github.com/PaddlePaddle/PaddleOCR
- EasyOCR: https://github.com/JaidedAI/EasyOCR
- 金鸣表格文字识别: https://www.jm189.cn/


 在线客服咨询
在线客服咨询 Ctrl+D 收藏本站
Ctrl+D 收藏本站